
深度学习中常用的正则化
Normalization 在深度学习中常被使用,它能够正则化神经网络中的输出数据,一定程度上消除内部协变量偏移(Internal Covariate Shift),加速网络训练,为初始化网络参数松绑,提高模型精度等。本篇介绍在深度学习中常用的正则化方法。
Batch Normalization
Batch Normalization 是对输入的的多个向量(即一批向量 $x_i,i=1,⋯,m$),对每个维度(特征)上进行正则化,也即每个神经元单独进行一批数据(分量)的正则化。首先计算该维度上的均值和标准差,然后该维度上各个分量减去均值再除以标准差。下面公式都是按照逐元素操作的。说白了,批正则化是针对每个神经元进行批次正则化。均值分母是批次大小。
$$
\mu_{\mathcal{B}} \leftarrow \frac{1}{m}\sum^m_{i=1} x_i
$$
$$
\sigma^2_{\mathcal B} \leftarrow \frac{1}{m}\sum^m_{i=1}(x_i - \mu_{\mathcal B})^2
$$
$$
\hat x_i \leftarrow \frac{x_i - \mu_{\mathcal B}}{\sqrt{\sigma^2_{\mathcal B} + \epsilon}}
$$
$$
y^i \leftarrow \gamma \hat x_i + \beta \equiv \mathbf{BN}_{\gamma, \beta}(x_i)
$$
其中 $\gamma, \beta$ 为可学习参数。最后一个公式表示反正则化,即与正则化相反,它能够通过参数进行反正则化,参数值是神经网络通过学习来决定的,所以,是否进行反正则化或者进行正则化是有神经网络对数据在学习中决定,这使得神经网络能够自动学习决定是否进行正则化,以适应数据。这些参数与原始模型参数一起学习,并恢复网络的表示能力。
下面给出一个实际例子,展示如何进行批正则化计算(前向),这里输入批次中包含两个向量 $x_1 = (1, 2, 3), x_2 = (4, 5, 6)$,对其进行批正则化,批次是 2,每个向量维数是 $1 \times 3$,按照算法,依照每个维度进行正则化计算。
1 | import numpy as np |
使用批正则化的好处是,一方面使得网络对初始化要求降低(初始化同时扩大K倍对于批正则化后的结果没有影响),另一方面,可以使用较大的学习率,增加收敛速度。
批正则化的提出是解决内部协变量偏移(Internal Covariate Shift, 简写为 ICS)的问题。所谓协变量偏移(Covariate Shift)是指当输入数据的分布在训练环境和实际环境之间发生变化时。尽管输入分布可能会发生变化,但输出分布或标签保持不变。在监督机器学习中,模型将通过离线或本地环境中的训练数据集学习输入和输出数据之间的关系。然后,该模型可用于使用它学到的模式进行预测或对新数据进行分类。当训练数据中的变量分布与现实世界或测试数据不同时,就会发生协变量偏移。这意味着模型一旦部署就可能会做出错误的预测,其准确率会明显降低。所谓内部协变量偏移 是指神经网络隐藏层的输入会因为学习参数导致与输出的数据分布不一致,而造成协变量偏移。也就是说训练过程中深度网络内部节点分布的变化称为内部协变量偏移。 Internal Covariate Shift 主要是由于训练过程中由于网络参数的变化而导致的网络激活分布的变化。
理想情况下,在整个训练集上进行正则化,但要将正则化与随机优化方法结合使用,使用全局信息是不切实际的。因此,在训练过程中,正则化被限制在每个小批量上。
批正则化不适用于 RNN 等动态网络,而且当批次较小时效果不好。
注意,推理阶段批正则化将发生改变。具体参考原论文。
Layer normalization
Layer norm (Layer Normalization)是由 Geoffrey E. Hinton 等于 16 年提出,来解决 Batch norm 的缺点(不能应用在 RNN 中)。对一个向量来做正则化。首先计算该向量的均值和标准差,然后用该向量的各分量减去均值再除以标准差。说白了,层正则化是针对数据进行该层神经元的正则化。均值分母是该层神经元的个数。
在批正则化中,隐层神经元有单独的均值和标准差,而在层正则化中,一个隐藏层中的神经元共享相同的均值和标准差。
训练和推断处理方式一致。
在卷积网络中,层正则化没有批正则化好,但在 RNN 中层正则化更好。
Instance normalization and Group normalization
Instance normalization 是2016年提出的,针对某一次输入某一个神经元的输出(特征图)进行正则化得到的。
Group Normalization 是由 Yuxin Wu 和 Kaiming He 于2018年在ECCV上发表的文章:Group Normalization 中提出的。它介于 Layer Norm 和 Instance Norm 之间。对通道进行分组,然后分布正则化。效果上较 Batch Norm 要好。
四者图示
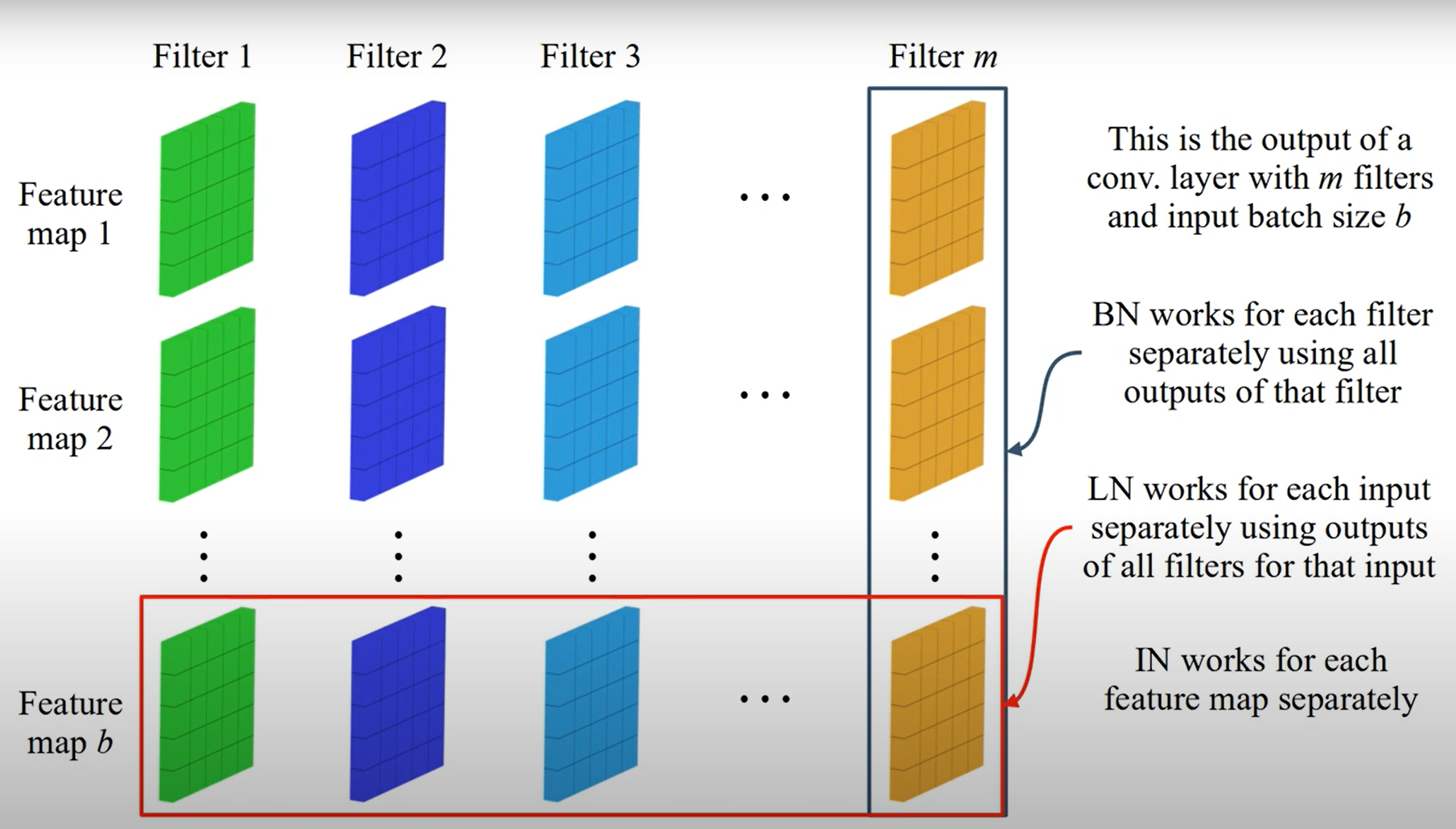

- Batch Norm 在 batch 的维度上正则化,正则化维度为 $[N,H,W]$,对 batch 中对应的 channel 正则化;
- Layer Norm 避开了 batch 维度,正则化的维度为 $[C,H,W]$;
- Instance Norm 正则化的维度为 $[H,W]$;
- Group Norm 介于 Instance Norm 和 Instance Norm 之间,其首先将 channel 分为许多 group,对每一个 group 做正则化。即先将 feature 的维度由 $[N, C, H, W]$ reshape 为 $[N, G,C/G , H, W]$,正则化的维度为 $[C/G , H, W]$.








