
计算机视觉之目标检测
目标检测是计算机视觉的一项基本任务。它能够告诉我们一幅图像中有什么(可能有多个)物体和这些物体在什么位置,位置常使用矩形框的形式给出。本篇我们介绍深度学习类目标检测算法及算法评估方法。
目标检测算法分类
目标检测算法发展至今已经有几十年,出现有多种类型的图像目标检测算法,包括
- 两阶段目标检测算法
- RCNN
- Fast RCNN
- Faster RCNN
- 单阶段目标检测算法
- YOLO 系列
- SSD
- RetinaNet
- FCOS
为了处理不同尺度目标的情况,很多深度学习目标检测算法都是基于锚框的,为了提高检测速度又发展出无锚框的算法:
- 有锚框算法
- Faster RCNN
- YOLO v2/v3
- SSD
- RetinaNet
- 无锚框算法
- YOLO v1
- FCOS
注意,RCNN 和 Fast RCNN 因采用常规算法(而不是 CNN)进行区域提议,因此,没有设置锚框。
两阶段目标检测算法的基本思路
对一幅图像进行目标检测要求同时预测出图像中的物体及位置,最容易想到的方法是先将图片均匀分块,然后使用图像分类算法对每一块图片补丁或图像块进行分类,图片补丁在原图像上的位置作为物体的位置信息。这种方法预测的物体边界框比较粗糙,如一个物体在跨两个图片补丁时,物体尺寸大于或小于补丁尺寸时,都是边界框的预测都是不准确的。
为了解决上面的物体跨补丁、固定尺寸导致的边界框粗糙问题,可以采用滑窗(Sliding Window)的思路。具体的使用不同尺寸、不同长宽比的矩形框窗口按照一定的步长(像素值)从图像左上角依次滑动取到图像的右下角。这样就可以得到很多个不同尺寸、不同长宽比的图片补丁,理论上原图片中的每个物体都能包含在这些图片补丁中。然后再对每一个图片补丁进行分类即可。或者固定窗口尺寸只采用不同长宽比,但是把原图像进行不同比例的缩放,即得到图像金字塔也可以获得理论上包含所有物体的图片补丁。这种方法也有缺点就是效率低,因为滑窗得到的图片补丁是很多的,对每一个图片补丁进行分类会很浪费时间和浪费计算资源,无法满足实时性的要求。
为了解决滑窗的效率问题,可以先对图片补丁进行筛选。因为滑窗得到的图片补丁包含大量的窗口都落在不包含物体的边界区域或物体内部。常用的方法是区域提议(Region Proposal),如 Selective Search 算法就是一种区域提议算法:使用贪心算法,将空间相邻且特征相似的图像块逐步合并到一起,形成可能包含物体的区域,称为提议区域或提议框。提议框的数量明显比滑窗得到的图片补丁少的多,然后使用这些提议框进行分类。使用提议框的边界坐标作为目标的物体的位置信息一般会有一些误差,此时,可通过一个回归分支进行位置信息预测,加上分类分支,整个模型是多任务学习模型。
RCNN
RCNN 是两阶段目标检测算法。对于一幅图像,第一阶段经过区域提议找出可能包含物体的框,区域提议采用 Selective Search 算法,该算法快但可能不是非常准确。第二阶段对区域提议框进行缩放到统一的尺寸得到 warped region,对每一个 warped region 使用卷积神经网络(AlexNet)得到图像特征,然后每一个图像特征先通过分类头(SVM分类器)预测物体类别,后通过回归头预测边界框偏移量。这一步因为需要对所有 warped region 输入卷积神经网络进行预测,所以比较慢但是准确。
对于第一阶段,区域提议是不需要学习参数的。第二阶段的卷积神经网络、分类分支和回归分支需要通过模型训练学习参数。学习时,训练顺序是先训练卷积神经网络,然后训练分类分支,最后训练回归分支,因此它不是端到端的、多任务学习。对于提议框 P = $(p_x, p_y, p_h, p_w)$(这里 $p_x, p_y$表示提议框的中心坐标,$p_h, p_w$ 表示高和宽)和标注框 B = $(b_x, b_y, b_h, b_w)$:
- 如果 P 和 B 的重叠较大,那么分类目标值就是B的标注类别,回归目标值就是 P 相对于 B 的偏移量;
- 如果 P 和 B 的重叠较小,那么分类目标值就是背景,回归分支不计算损失。
其中边界框的偏移量,即回归分支的预测目标为:
$$(t_x, t_y, t_h, t_w) = (\frac{b_x - p_x}{p_w}, \frac{b_y - p_y}{p_h}, \log(\frac{b_w}{p_w}), \log(\frac{b_h}{p_h}))$$
前两个元素表示位置偏差基于边长归一化,后两个元素表示尺度比例的对数。编码后的偏移量既可以避免绝对数值过大或过小影响,又可以把他们的数值编码到一个比较容易预测的范围。
两个矩形框的交并比 IOU 定义为它们的交集面积与并集面积的比值,是对两个矩形框重合度的衡量。
非极大值抑制(Non-Maximum Suppression,NMS)对于一个目标类,有时会得到多个预测框,每个预测框对应不同的置信度值。使用非极大值抑制算法,我们可以得到每个目标一个预测框:
- 输入:检测器产生的一系列检测框 P = ${P_1, \cdots, P_n}$ 及对应的置信度 s = ${s_1, \cdots, s_n}$,IOU 阈值 $t$
- 步骤:
- 初始化结果集 R = $\emptyset$
- 重复直至 P 为空集
- 找出 P 中置信度最大的框 $P_i$ 并加入 R
- 从 P 中删除 $P_i$ 以及与 $P_i$ 交并比大于 $t$ 的框
- 输出: 结果集 R
这里说一下为什么要用非极大值抑制。当我们知道一副图像中每一类(如人)的对象只有一个时,可以用该类预测置信度最高的那个目标框来表示该类对象。但是,通常情况下,一副图像中每一类的对象可能不止一个,比如一副图像中出现多个人(或人脸),此时,对于人(或人脸)的类别有多个预测框(和置信度),我们可以通过非极大值抑制算法找到该类每个对象的(局部)最大的检测框。
Fast RCNN
2014 年,针对 RCNN 中多个提议框都需要进行一次卷积神经网络导致模型推断速度慢的问题,提出了 RoI Pooling 方法(Region of Interest),把提议区域从图像移动到特征图上,这样只需要对整个图像进行一次卷积神经网络特征提取,把提议框通过 RoI Pooling 直接映射到特征图上,一次得到所有提议框的卷积后的特征。这大幅降低了计算量。
对于图像上的提议框,通过简单的几何比例缩放把提议框映射到特征图上。然后通过 RoI Pooling 将提议框内不定尺寸的特征图变成固定尺寸。下面重点介绍 RoI Pooling:
- 给定全图的特征图和一些列提议框(缩放到全图特征图上的提议框),将提议框区域按照宽、高均匀切分成固定数目的格子(常用 $7\times 7$);
- 对于每个格子,如果格子边界不在整数坐标,则膨胀至整数坐标;
- 对于每个格子,通过 Max Pooling 得到格子的输出特征。
这样通过 RoI Pooling 将任意尺寸的提议框映射到固定宽、高的提议特征图,同时保留图像特征。
Fast RCNN 推断的基本流程是:
- 使用 Selective Search 进行区域提议;
- 原图通过 CNN 得到全图特征图;
- 将原图上的提议框按照几何比例缩放到特征图上,几何比例是原图到 CNN 输出的特征图的比例;
- 利用 RoI Pooling,将不同尺寸的特征图变换到相同大小;
- 基于相同尺寸的特征图进行分类和回归。
Faster RCNN
2015 年,针对 Fast RCNN 中运行最慢的 Selective Search 区域提议模块,提出了基于卷积神经网络的 RPN (Region Proposal Network) 网络,产生区域提议,进一步提高了效率。
RCNN 在推理时,一副图像大概需要 49 秒,当排除区域提议步骤时,大概需要 47 秒。Fast RCNN 在增加了 RoI Pooling 并将提议框特征共享主干网络后,一副图像的推理大概需要 2.3 秒,当排除区域提议步骤时,大概需要 0.32 秒。因此,依赖 Selective Search 产生区域提议框的步骤成为了 Fast RCNN 的速度瓶颈。在 Faster RCNN 中使用 CNN 代替 Selective Search 来产生提议框,并与检测器共享主干网络结构。
RPN 就是用于在图中找到有物体的提议框,属于单类别(物体和背景)物体检测的问题。具体地:
- 图像经过 CNN 主干网络得到全图特征图;
- 设置锚框(在原图上设置不同大小的假想框,用不同检测头检测对应框中是否出现物体)来处理不同窗框比,不同大小的物体;
- 使用检测头(轻量级的卷积核)在全图特征图上进行密集滑窗,产生区域提议(分类和边界框回归);
- 集合所有提议框,使用 NMS 得到最终的提议框特征。
Mask RCNN
2017 年针对 Fast RCNN 中提出的 RoI Pooling 回归效果差问题,提出了 RoI Align 提高边界框预测精度。同时,加入 Mask 分支,使得模型能够用于实例分割。
RoI Pooling 对于非整数边界框(如对一个尺寸为 $20\times 20$ 的提议特征图按照宽、高均匀划分 7 等分得到一个 $7\times 7$ 的小矩形块,此时,20 无法整数 7,就会造成边界框不是在整数边界上)取整,产生位置偏差。Roi Align 为了保留空间精度,使用“非整数坐标”的特征。具体地,对于划分后的小矩形块,例如取该小矩形块中心点的像素值,中心点可能不在某个具体的(整数)像素或特征上,通过插值的方法可以获取到该中心点周围的四个点的双线性插值,表示该中心点的像素或特征值。
RoI Align:
- 将映射到全图特征图上的提议区域均匀切分成固定数目的格子(常用 $7\times 7$);
- 在每个格子中,均匀选取若干采样点,如 4 个;
- 通过插值方法得到每个采样点处的精确特征;
- 所有采样点做 Pooling,如 Max Pooling,Average Pooling,得到输出结果。
RoI Align 比 RoI Pooling 在位置上更精细。
FPN
RCNN 类目标检测算法是只采用单级高层特征(通常是主干网络最后一层或倒数第二层)做预测,但是对于小目标检测效果不好。高层特征语义信息比较丰富,目标位置预测比较粗糙,低层特征语义信息较少,目标位置预测较准确。高层特征空间降采样率较大,容易造成小物体信息丢失。特征金字塔 FPN (Feature Pyramid Network) 通过融合底层和高层特征进行预测。具体地,
- 一副图像经过主干网络产生多层次的特征;
- 对最后一层特征进行上采样,使得空间分辨率与前一层特征相同,然后与前一层特征(经过 $1 \times 1$ 卷积核调整通道数)进行融合(各通道各位置像素值相加);
- 融合后的特征再重复步骤 2 的操作,得到特征金字塔。
单阶段目标检测算法的基本思路
在上面的两阶段目标检测算法中,除了图像经过主干网络进行全图特征图提取外主要分成 2 个部分,一部分是基于全图特征图采用不同尺度的锚框进行区域提议阶段,另一部分是基于提议的区域特征图进行区域识别检测阶段。本部分介绍单阶段目标检测算法,它没有区域提议阶段,直接基于全图特征图产生类别和边界框预测。因为缺少了提议阶段,其推理速度快,结构简单,易于在不同设备上部署。但多数情况下性能不如两阶段算法。
常见的单阶段检测算法有 YOLO 系列(基于特征图直接回归边界框)、SSD (基于多尺度特征图与锚框)、RetinaNet (提出 Focal Loss,解决样本不均衡问题)、FCOS (多尺度特征图直接回归)
YOLO
YOLO (You Only Look Once) 是 2015 年提出,是最早的单阶段算法之一,使用 DarkNet 结构的主干网络产生特征图,利用全连接层产生全部空间位置的预测结果,每个位置包含 $C$ 维(一个类别一个概率)分类概率和 $B$ 组边界框预测(每一个边界框包含 $x, y, w, h, score$),所以输出向量为 $5B + C$ 维(或通道)。
具体地,将原图切分成 $S \times S$ 个大小的格子,对应预测特征图上 $S \times S$ 个像素的位置。如果原图上一个物体的中心落在某个格子内,则特征图上对应像素位置应给出该物体的类别和边界框的位置预测。其余位置应预测为背景类别,不关心边界框预测结果。预测特征图每一个像素为 $5B+C$ 维(或通道),包含 $B$ 个框和 $C$ 个类别预测。当类别预测为非背景时,边界框预测的 $x, y$ 为边界框中心点相对于格子边界的偏移量,$w, h$ 为边界框的相对原图大小,分数 $score$ 为预测框与真值框的 IOU 分数值。当类别预测为背景时,边界框不计算损失。
YOLO 是一个多任务学习问题,其损失函数包含回归、分类计算,通过超参数 $\lambda$ 来控制权重分配。
第一部分,当边界框需要产生类别(物体/背景)预测时,计算 IOU 分数或置信度的回归损失:
$$ L_1 =\sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{obj}(C_i-\hat{C}_i)^2 + \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{noobj}(C_i - \hat{C}_i)^2, $$第二部分,当边界框需要产生物体预测时,计算边界框坐标的回归损失:
$$ L_2 = \lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}\mathbb{1}^{obj}_{ij} [ (x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2] + \lambda_{coord}\sum^{S^2}_{i=0}\sum^{B}_{j=0}\mathbb{1}^{obj}_{ij} [ (\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2], $$第三部分,当边界框需要产生物体预测时,计算 $C$ 个类别概率的回归损失:
$$ L_3 = \sum^{S^2}_{i=0}\mathbb{1}^{obj}_{i}\sum_{c\in classes} (p_i(c) - \hat{p}_i(c) )^2, $$整个模型的损失函数为:
$$
L = L_1 + L_2 + L_3.
$$
YOLO 的优点:
快!在 Pascal VOC 数据集上,使用 DarkNet 结构可以达到实时的速度。使用相同的 VGG 可以达到 3 倍于 Faster RCNN 的速度:
检测算法 主干网络 训练集 检测精度(mAP) 检测速度(FPS) Fast YOLO 9层DarkNet VOC 2007 + 2012 52.7 155 YOLO 24层DarkNet VOC 2007 + 2012 63.4 45 Faster RCNN VGG16 VGG 16 VOC 2007 + 2012 73.2 7 YOLO VGG16 VGG 16 VOC 2007 + 2012 66.4 21
YOLO 的缺点:
- 由于每个格子只能预测 1 个物体,因此对于重叠物体、尤其是大量重叠的小物体容易产生漏检;
- 直接回归边界框难度大,回归误差较大。
YOLO v2
针对 YOLO v1 的缺点,作者进行了模型改进,提出新的 DarkNet-19 结构的主干网络,加入 BN;同时,加入锚框,使用聚类方法设定锚框尺寸。
YOLO v3
提出加入残差结构的主干网络 DarkNet-53;同时,加入类 FPN 结构,基于多尺度特征图预测。
SSD
主干网络采用 VGG 结构(只保留前 4 级卷积层) + 额外的卷积层,产生多尺度的特征图,每层特征图包含了不同尺度物体的信息。检测头是在每级特征图上,使用 $3\times 3$ 卷积层产生 $(c + 4)a$通道的预测图,共有 $a$ 个锚框,每个锚框预测 $c$ 个分类概率,$4$ 个边界框偏移量。
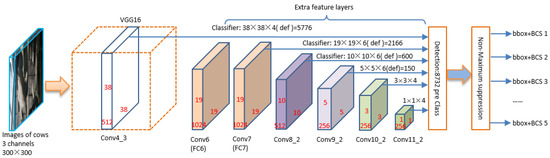
训练时,首先产生正负样本:
- 对于每个真值框,把它和交并比最大的锚框进行匹配;
- 将剩余的每个锚框与交并比大于 0.5 的真值框进行匹配。
一个真值框可匹配多个锚框
然后,计算损失函数:
- 匹配的锚框为正样本,计算分类和边界框回归损失;
- 其余框为负样本,仅计算分类损失。
上面锚框和真值框匹配容易造成正负样本不均衡问题,即锚框的数量远远大于真值框(数万 VS 数个),大量锚框为负样本。检测头中的分类器面临正负样本不均衡问题,容易使模型对背景预测产生偏向性。两阶段的区域提议会拒绝大量的负样本,在单阶段的过程中,因为没有该过程,需要专门处理样本不均衡问题 :
- YOLO 对正负样本的损失使用不同的权重;
- SSD 在训练过程中使用困难负样本挖掘(Hard Negative Mining)策略;
- (下面将会介绍的)RetinaNet 使用 Focal 损失函数。
困难样本是分类器难以分类正确的样本,即损失比较大的样本。负样本是真值为背景的样本。困难负样本就是真值为背景,但分类器分类为前景,且置信度非常高的样本。这些样本可能是位于真值框附近,但 IOU 并不高的候选框,也可能是位于背景区域,但形状或纹理非常类似前景物体的候选框。
困难负样本挖掘:
- 为应对样本不均衡问题,SSD 在每次训练迭代中,仅选取分类损失最大的一部分负样本参与最终损失计算,正负样本比例保持在 1:3;
- 困难负样本挖掘是一个动态的过程,分类器参数更新后,困难负样本也随之变化
RetinaNet
针对样本不均衡问题,2017 年 提出的 RetinaNet 利用 Focal Loss 解决样本不均衡问题。Focal 损失函数可以让正、负、简单、困难样本产生相对均衡的损失,从而解决样本不均衡的问题。
对于二分类交叉熵损失函数 CE Loss:
$$
CE(p, y) = \begin{cases}
-\log(p), & \text{if } y = 1; \\
-\log(1-p), & \text{otherwise}.
\end{cases}
$$
这里 $p$ 是模型输出的正类概率。为了简化公式,设 $p_t$ 为:
$$
p_t = \begin{cases}
p, & \text{if } y=1;\\
1 - p, & \text{otherwise}.
\end{cases}
$$
此时,损失函数可以改写成:
$$
CE(p_t) = -\log{p_t}.
$$
Focal Loss 定义为:
$$
FL(p_t) = -\alpha_t(1-p_t)^{\gamma}\log{p_t}.
$$
对于正负样本不均衡,采用在损失函数中增加正样本的权重,减少负样本的权重的方法。具体地,引入加权因子 $\alpha \in [0, 1]$ 对正负样本的损失进行加权,定义:
$$ \alpha_t = \begin{cases} \alpha, & \text{正样本}; \\ 1 - \alpha, & \text{负样本}. \end{cases} $$对于困难样本和简单样本不均衡,采用的方法是在交叉熵的基础上增加调节因子 $(1-p_t)^{\gamma}$ ,其中 $\gamma$ 是可调节的参数:
$$ -(1-p_t)^{\gamma}\log p_t. $$原理是:
- 困难样本对应的 $p_t$ 接近 0, 调节因子对损失几乎没有影响;
- 简单样本对应的 $p_t$ 大多落在 [0.6, 1.0] 区间,调节因子大幅降低损失;
- 二者共同作用,简单样本的损失比重降低。
综合起来,Focal 损失函数 $-\alpha_t(1-p_t)^{\gamma}\log p_t$ 通过 $\alpha$ 来调节正负样本的权重,$\gamma$ 来调节简单样本权重降低的速率。值得注意的是,不同数据集超参数 $\alpha, \gamma$ 是不同的,需要根据情况调整。
基于 Focal 损失,单阶段检测模型 RetinaNet:
- 使用 ResNet 作为主干网络,利用 FPN 参数多尺度特征图;
- 在每级特征图上设置锚框
- 有两个分支(分别为分类和边界框回归)、4 层卷积构成的检测头,针对每个锚框产生$K$类类别预测和 4 个边界框偏移量预测。
FCOS
2019 年提出的 FCOS 既是单阶段目标检测算法又是一类无锚框目标检测算法。在基于锚框的目标检测算法(如 Faster RCNN, YOLO v2/v3, RetianNet等)中,锚框引入了大量超参数(如锚框大小、锚框长宽比、匹配 IOU 阈值等),需要根据经验人工调整,同时锚框涉及较复杂的计算,如锚框与真值框的匹配等。相反地,无锚框算法尝试直接基于特征学习边界框的位置,不依赖锚框,从而降低模型复杂度。值得一提的是,虽然 YOLO v1 是无锚框算法,但由于提出时间较早,相关技术并不完善,性能不如基于锚框的算法。
FCOS 通过主干网络与特征金字塔产生多尺度特征图,使用检测头在多级特征图上完成预测,对于每个位置,预测类别、边界框位置和中心度三组数值。它的基本规则是:
- 如果特征图上某个位置(在原图上对应的位置)位于某个物体的边界框内部,则该位置的预测值应给出该物体的类别、边界框相对于该位置的偏移量、中心度(用于衡量预测框的优劣);
- 如果某个位置不在任何物体的边界框内部,分类为背景。
对于重叠物体的处理:
- YOLO v1 直接回归边界框,但不能处理重叠物体;
- 基于锚框的算法可以基于不同的锚框,产生不同目标物体的预测;
- FCOS 认为重叠物体尺度通常不同,有不同尺度的特征图给出对应目标物体的预测。小物体的预测基于低层次特征图给出;大物体的预测基于高层次特征图给出。但是,如果同层特征图中还有重叠,预测重叠物体中较小的那个。
中心度(Center-ness)。FCOS 将所有框内的位置归类为正样本,这有助于产生更多正样本用于训练,但也会让分类器更容易在物体周围产生低质量预测框。因此,提出中心度的概念:
- 每个位置额外预测一个中心度值,表示该预测框的位置优劣;
- 推理阶段:$\text{置信度}=\sqrt{\text{中心度}\times \text{分类概率}}$.
具体地,中心度定义为:
$$ \text{centerness}^* = \sqrt{\frac{\min(l^*, r^*)}{\max(l^*, r^*)}\times \frac{\min(t^*, b^*)}{\max(t^*, b^*)}} $$其中,$l^*, r^*, t^*, b^*$ 分别表示该特征点距离真实边界框的左、右、上、下在原图上的距离。
中心度的几何意义是位置越靠近边界框中心越接近 1,越靠近边界越接近 0。
FCOS 的损失函数:
- 每个位置的分类损失 $L_{cls}(p_{x,y},c_{x,y}^*)$,使用 Focal loss;
- 对于前景样本的边界框回归损失 $L_{reg}(t_{x,y},t_{x,y}^*)$,使用 IoU loss:$-\ln IoU$;
- 对于前景样本的 Center-ness 值,因为介于 0-1 之间,使用 BCE loss.








