
Transformer
Transformer 是一种 Seq2seq 模型,即 input a sequence, output a sequence. 应用包括语音识别(输入语音,输出文本)、机器翻译(输入一种语言文本,输出另一种语言文本)、语言翻译(输入一种语言的语音,输出是另一种语言的文本,如字幕)、语音合成(输入一种语言文本,输出另一种语言的语音)、聊天机器人(对话)等,这些都可以看作 QA(Question & Answering)问题,都可以使用 Seq2seq 模型解决。
Seq2seq
一般的 Seq2seq 模型的一般框架
1 | input sequence -> Encoder -> Decoder -> output sequence |
如 Transformer 就是该模型的一种。李宏毅老师的课件:Transformer
Self-attention
self-attention 中文是自注意力,它对于输入的向量输出相同数量的向量。
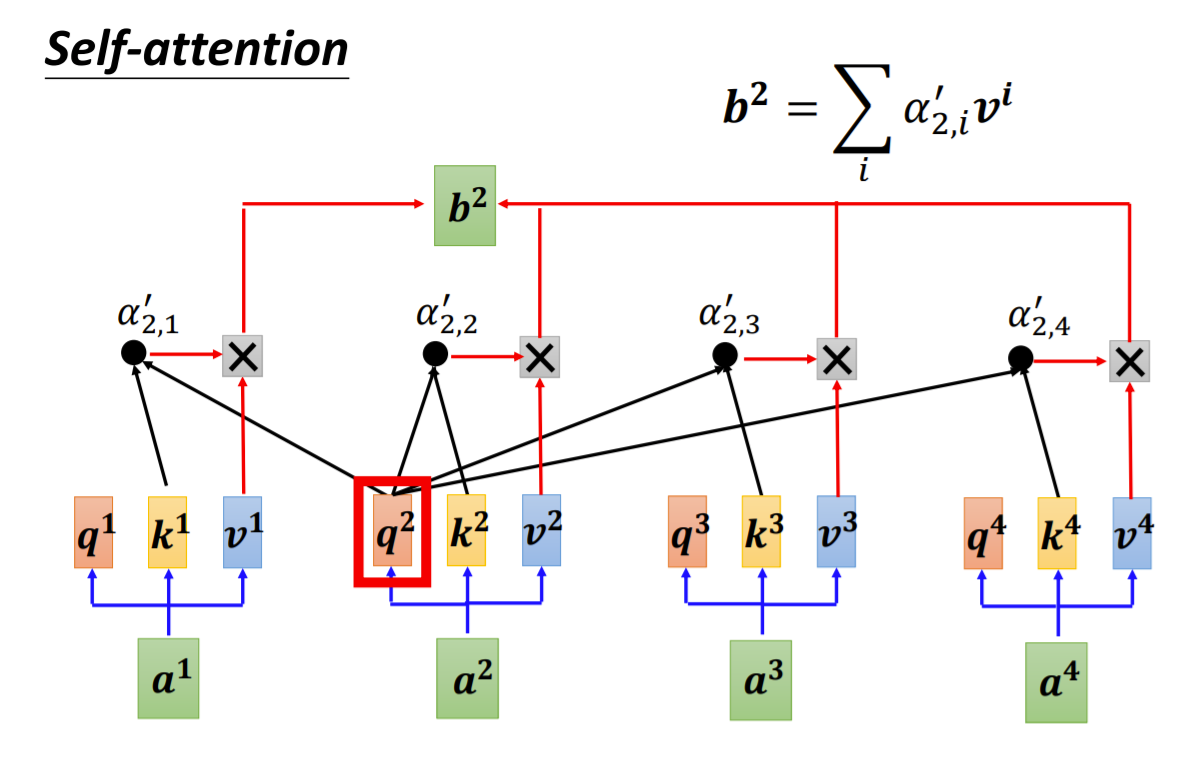
如上图所示,$a^i, i = 1, 2, 3, 4$ 为输入向量(如词嵌入向量),$q^i, i = 1, 2, 3, 4$ 为 query,$k^i, i = 1, 2, 3, 4$ 为 key,$v^i, i=1, 2, 3, 4$ 为 value,后三者分别有输入向量 $a^i$ 得到
$$
q^i = W^q a^i
$$
$$
k^i = W^k a^i
$$
$$
v^i = W^v a^i
$$
这里,$W^q, W^k, W^v$ 是矩阵,但不一定是方阵,一般是行大于列。行数代表输入向量的维数,列代表乘积后输出的向量 $q^i, k^i, v^i$ 维数。
而 $\alpha_{2, 1}$ 是由 $q^2$ 与 $k^1$ 做 dot product 而得到的,其他依次类推 $\alpha_{2,2}, \alpha_{2, 3}, \alpha_{2, 4}$. 然后,通过 Softmax 激活函数,得到 $\alpha_{2, i}^{\prime}, i = 1, 2, 3, 4$ 作为系数与 $v^i, i = 1, 2, 3, 4$ 相乘得到 $b^2 = \sum_i \alpha_{2, i}^{\prime} v^i$,对于其他 $b^1, b^3, b^4$ 依次类推。
其实,Self-attention 能够利用矩阵简洁表示如下,这也是其并行化计算的原因
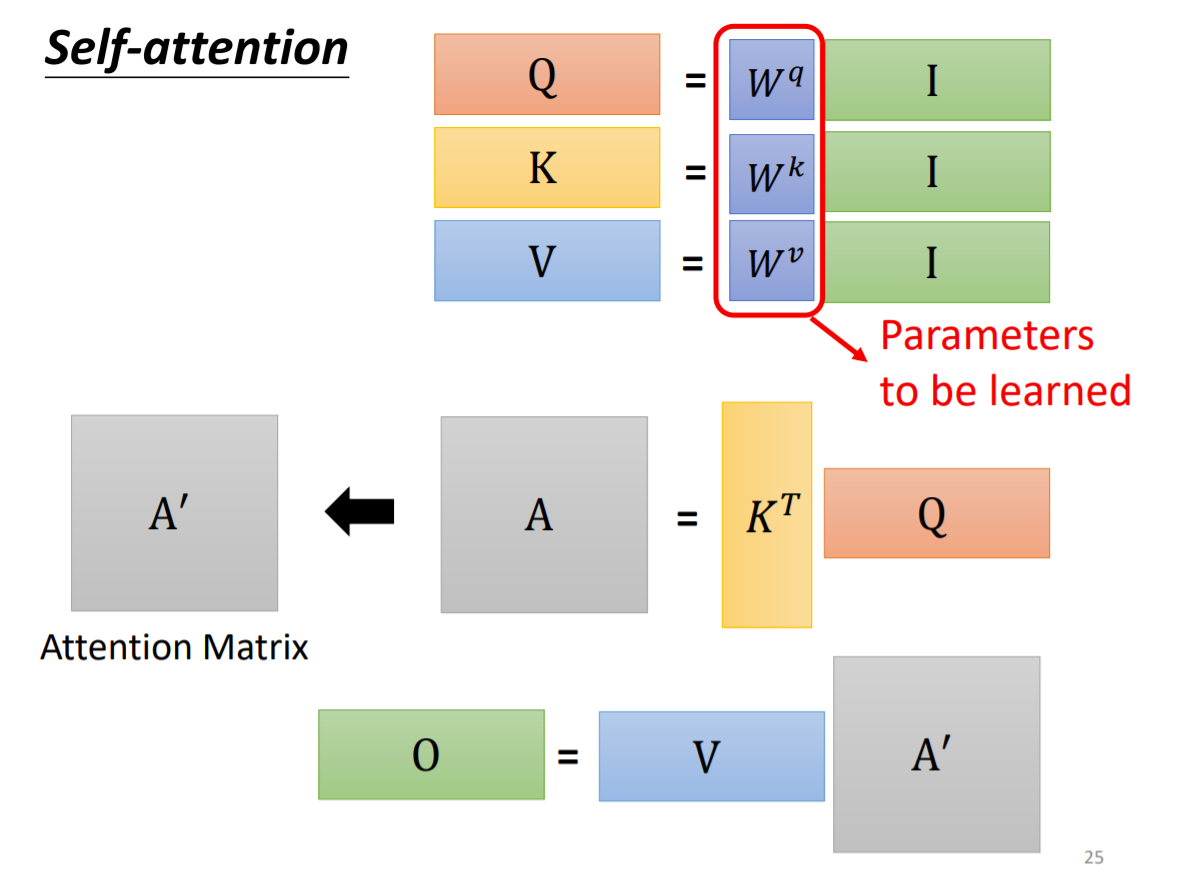
这里 $I = (a^i), i = 1, 2, 3, 4$ 为输入向量列,$W^q, W^k, W^v$ 为需要学习的参数矩阵,$Q, K, V$ 分别为 query, key, value 矩阵,$A$ 为 attention 系数,$A^{\prime}$ 为经过 Sigmoid 归一化后的 attention matrix. $O = (b^i), i = 1, 2, 3, 4$ 为 self-attention 输出的向量列。
在实际使用中,常常采用 multi-head self-attention,如下图所示
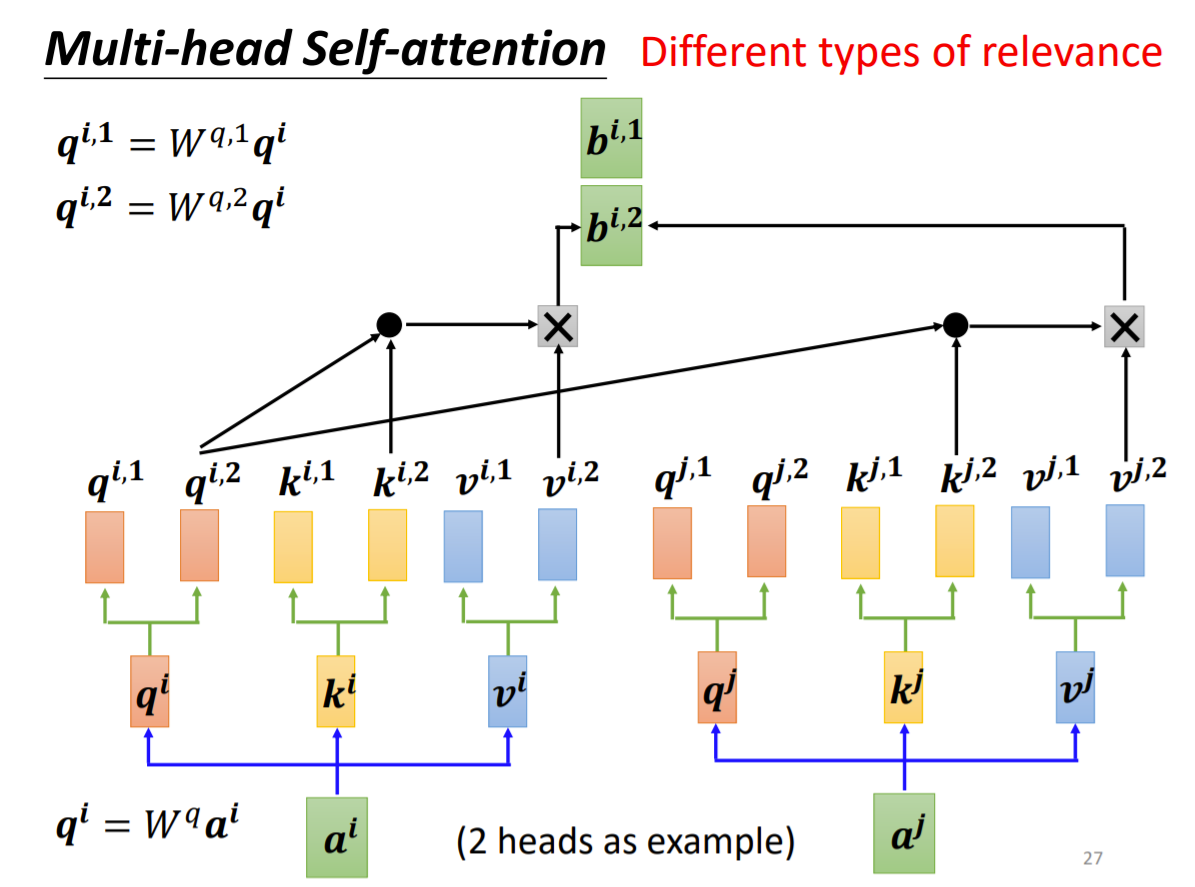
与上面的 self-attention 类似,先通过 $W^q, W^k, W^v$ 得到 $q^i, k^i, v^i$,然后再分别经过 2 个(这里例子 multi-head 为 2 头的)矩阵得到 2 个
$$
q^{i, 1} = W^{q, 1}q^i, q^{i,2} = W^{q,2}q^i
$$
$$
k^{i, 1} = W^{k, 1}k^i, k^{i,2} = W^{k,2}k^i
$$
$$
v^{i, 1} = W^{v, 1}v^i, v^{i,2} = W^{v,2}v^i
$$
那计算 $b^{i,2}$ 时,只需要 $q^{i,2}$ 与 $k^{j,2}, j = 1, 2, 3, 4$ 相乘后然后经过 Sigmoid 归一化后得到 attention 系数,然后组合 $v^{i,2}$ 相乘得到
$$
b^{i,2} = \sum_j \alpha^{\prime}_{i, 2, j} v^{j, 2}
$$
注意,这里只需要计算相同头(如 $(q^{i,1}, k^{i,1}, v^{i,1}), (q^{j,1}, k^{j,1}, v^{j,1})$,相同标号 1)的值,计算方法同上面的 selft-attention.
最后,$b^i = W^0 (b^{i,1}, b^{i,2})^T$ .
这样,就从 $a^i, i = 1, 2, 3, 4$ 得到 $b^i, i = 1, 2, 3, 4$.
CNN 和 Self-attention 的关系:On The Relationship Between Self-attention And Convolutional Layers
Encoder
输入一排向量,输出另一排同样长度的向量。在 Transformer 中的 Encoder 里用的是 Self-attention.
BERT 是仅仅使用 Transformer 的 Encoder 构建起来的。
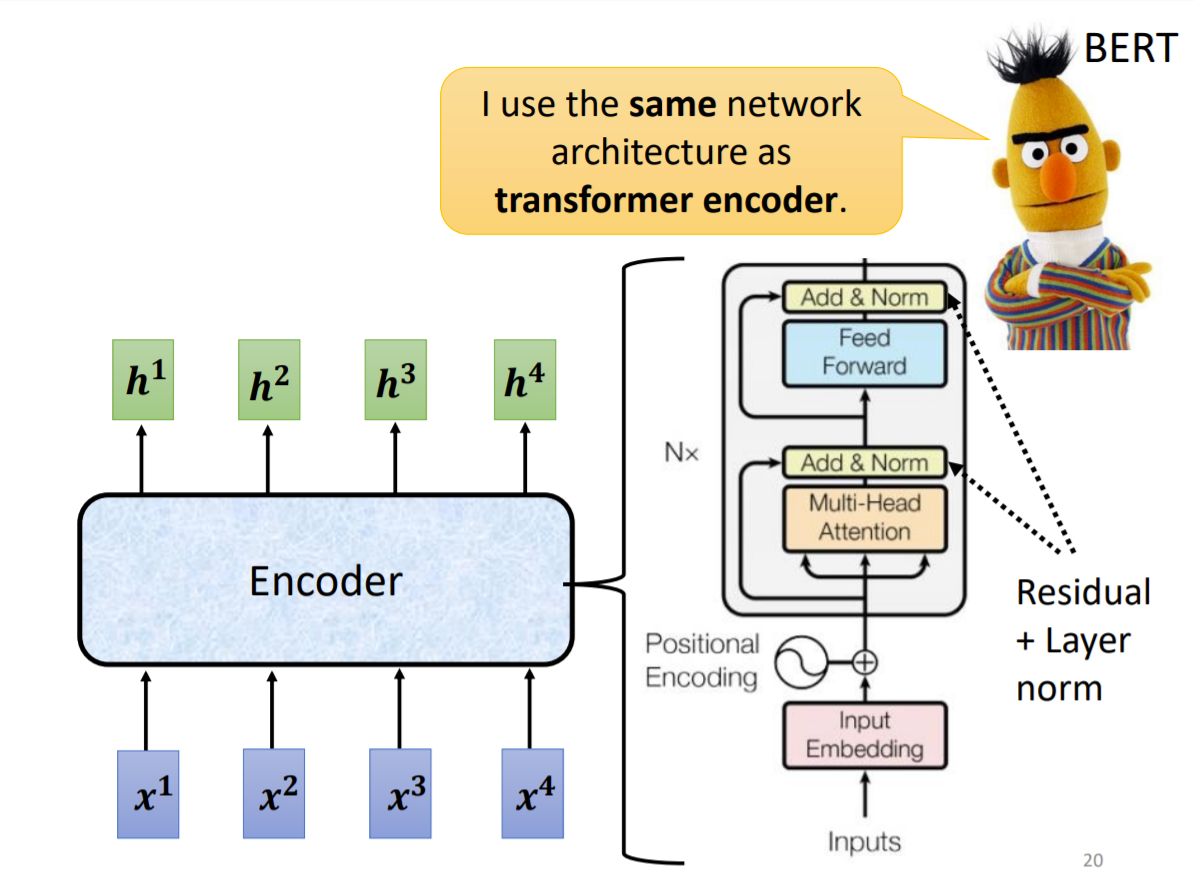
Encoder 是由 $N$ 个 self-attention 模块线性拼接而成,输入向量列增加了位置信息。
Decoder
输入是 Encoder 的输出向量和一个 special token (标识开始 BEGIN)。
GPT-2, GPT-3 是仅仅使用 Transformer 的 Decoder 构建起来的,属于 Unsupervised Pre-training model。 在 300 billion tokens of text 上训练得到,它的目标(能够做)Predict the next word.
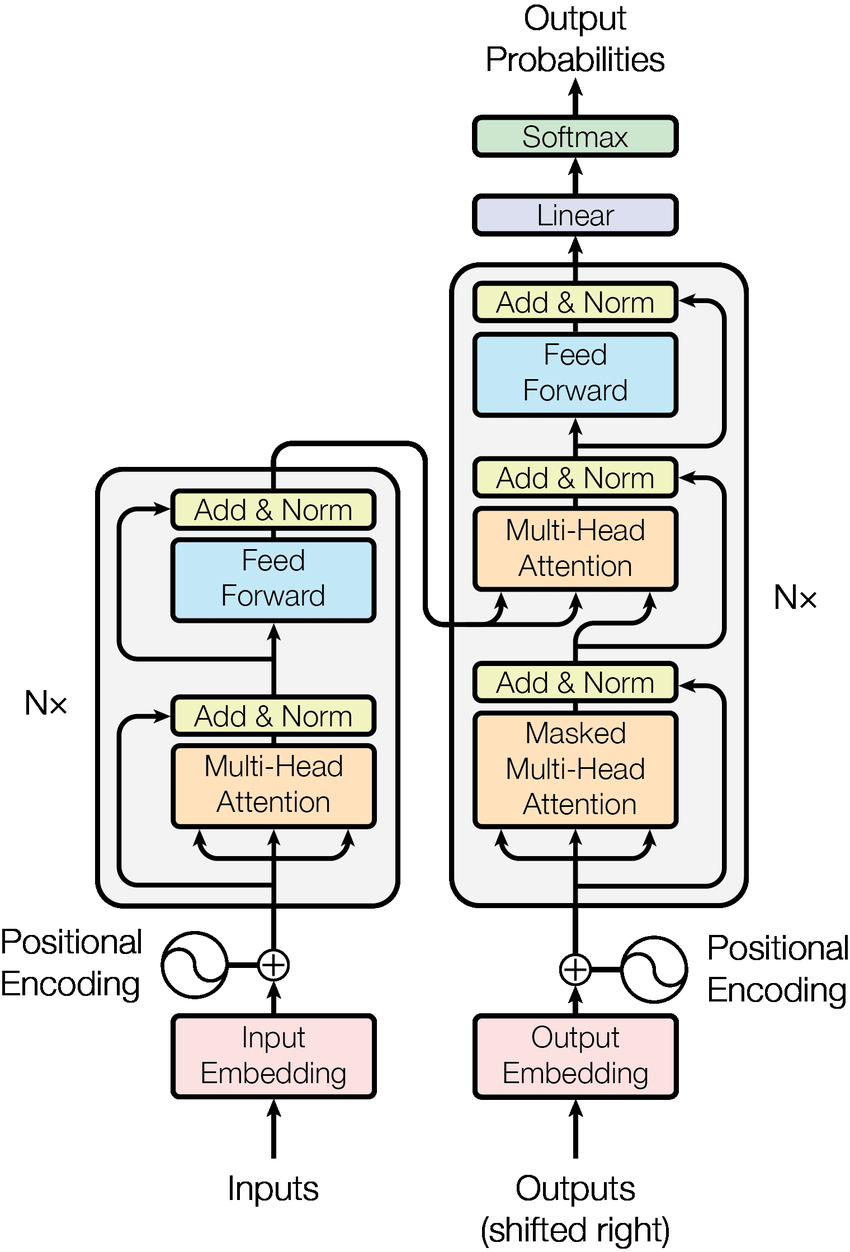
Decoder 与 Encoder 的区别是调整为 masked multi-head attention,并在中间增加 cross attention,引入 encoder 的信息。而 masked multi-head attention 是因为后面的单词或向量还未得到,不能像 encoder 里的 multi-head attention 那样使用全面的向量的信息,只能使用已经得到的向量的信息。
在 cross attention 中,对于 decoder 中 masked multi-head attenion 得到的每一个 $q$ 分别与 encoder 中的 $k^i = W^k a^i, v^i = W^v a^i$ 做 self-attention 操作得到 $v$,如图所示
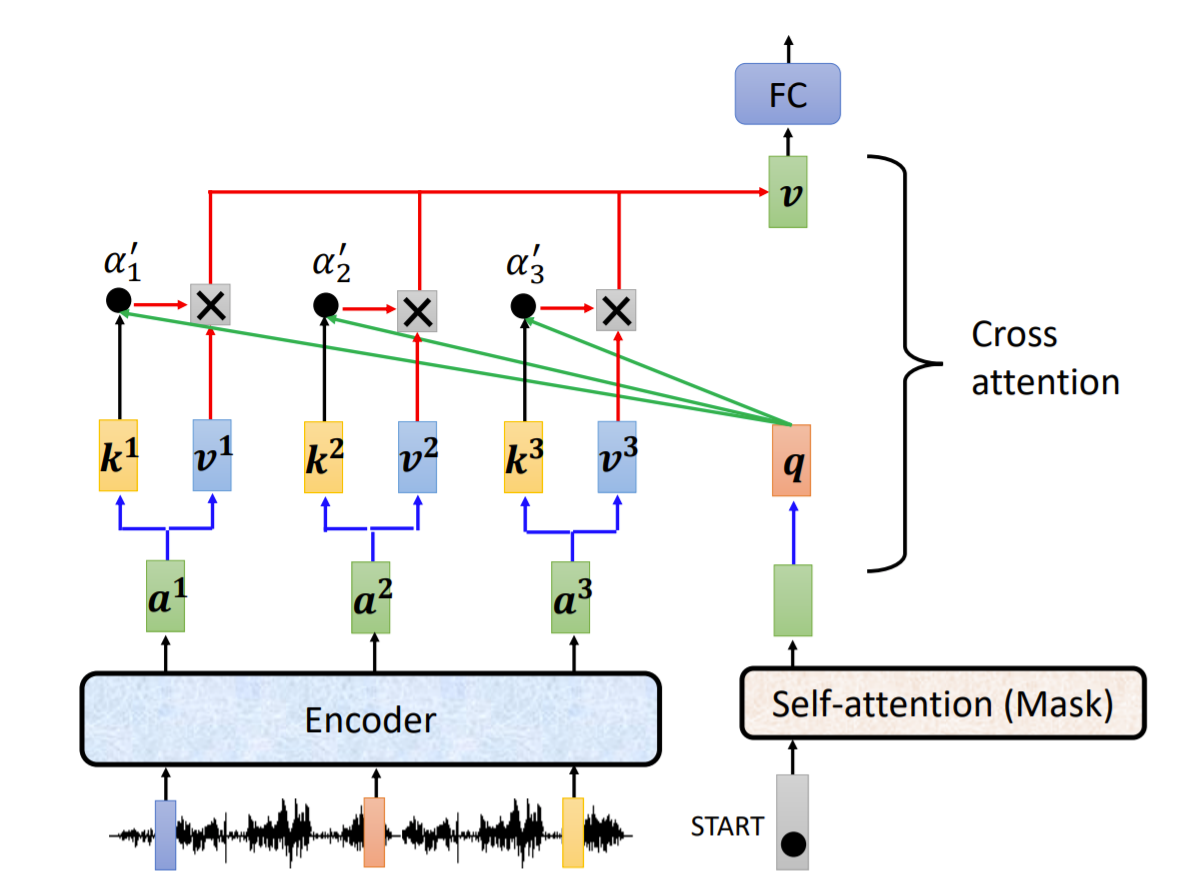
$$
v = \sum_{i=1}^{3}v^i * \alpha_{i}^{\prime} \\
\alpha_{i}^{\prime} = f(k^i * q / \sqrt{d}) \\
$$
这里映射 $f$ 表示 sigmoid 激活,$d$ 表示 $q$ 的维度。
代码实现
TensorFlow: tensor2tensor
pyTorch: The Annotated Transformer








